This expectation brings us to one of the most important ideas in system design, availability. Let us break it down in a way that actually makes sense.
What is Availability?
Availability is simply the ability of a system to stay usable even when things go wrong.
Failures are normal in distributed systems. Servers crash, networks slow down, and disks fail. A highly available system is designed so users can continue using it despite these failures.
We usually measure availability as uptime percentage.
Formula
Availability = Uptime / (Uptime + Downtime)
- Uptime: when the system is working and reachable.
- Downtime: when the system is not usable because of failures, maintenance, or outages.
Real World Analogy
Think about an ATM network.
- If ATMs are working most of the time, availability is high.
- If ATMs are frequently out of service, availability is low.
Users do not care why it failed. They care whether they can withdraw money.
The Nines of Availability
Availability is often expressed in terms of how many nines appear in the uptime percentage.
| Availability | Downtime per Year (approx.) |
|---|---|
| 99% (two nines) | 3.65 days |
| 99.9% (three nines) | 8.7 hours |
| 99.99% (four nines) | about 52 minutes |
| 99.999% (five nines) | about 5 minutes |
Moving from 99% to 99.999% is not a small improvement. It usually requires redundancy, automation, monitoring, failover systems, and distributed infrastructure. This directly increases system complexity and cost.
Availability of Components: Sequence vs Parallel
Systems are made of multiple components such as databases, APIs, load balancers, and caches. How you connect them affects overall availability.
Components in Sequence
If one component fails, the whole system fails.
User → API → Database
If API availability is 99.9% and database availability is 99.9%, then total availability is about 99.8%. Adding dependencies can reduce availability.
Components in Parallel
Parallel components increase availability because backups exist.
User → Load Balancer → (Server A OR Server B)
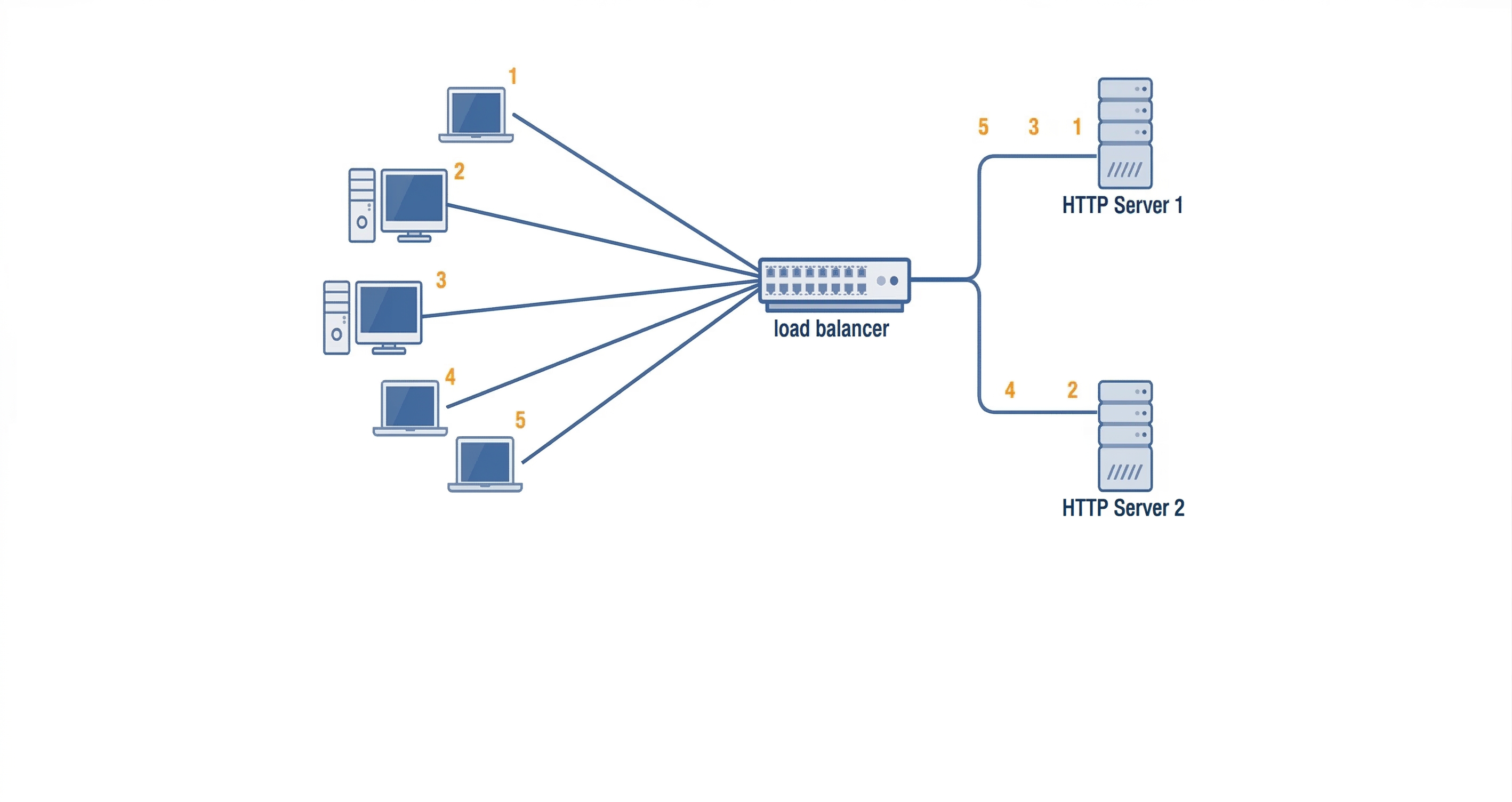
If both servers have 99.9% availability, combined availability becomes much higher because both servers must fail at the same time for the system to go down.
Availability vs Reliability
These terms sound similar but they are different.
- Reliability: the system runs without failure for a long time.
- Availability: the system is usable when the user needs it.
A system can be reliable but not highly available, or highly available but not very reliable.
Example: a streaming service may crash occasionally but recover in seconds. Users still feel the service is always available.
High Availability vs Fault Tolerance
Both aim for uptime, but the approach is different.
Fault Tolerant System
- No interruption at all.
- Instant hardware replacement.
- Very expensive.
Example: aircraft control systems.
Highly Available System
- Small interruptions are allowed.
- Fast recovery.
- Practical for large internet systems.
Example: ecommerce platforms.
Most internet systems target high availability, not full fault tolerance.
Availability Patterns
To achieve high availability, engineers use architectural patterns. Two major ones are failover and replication.
Failover
Failover means having a backup system ready to take over when the main system fails.
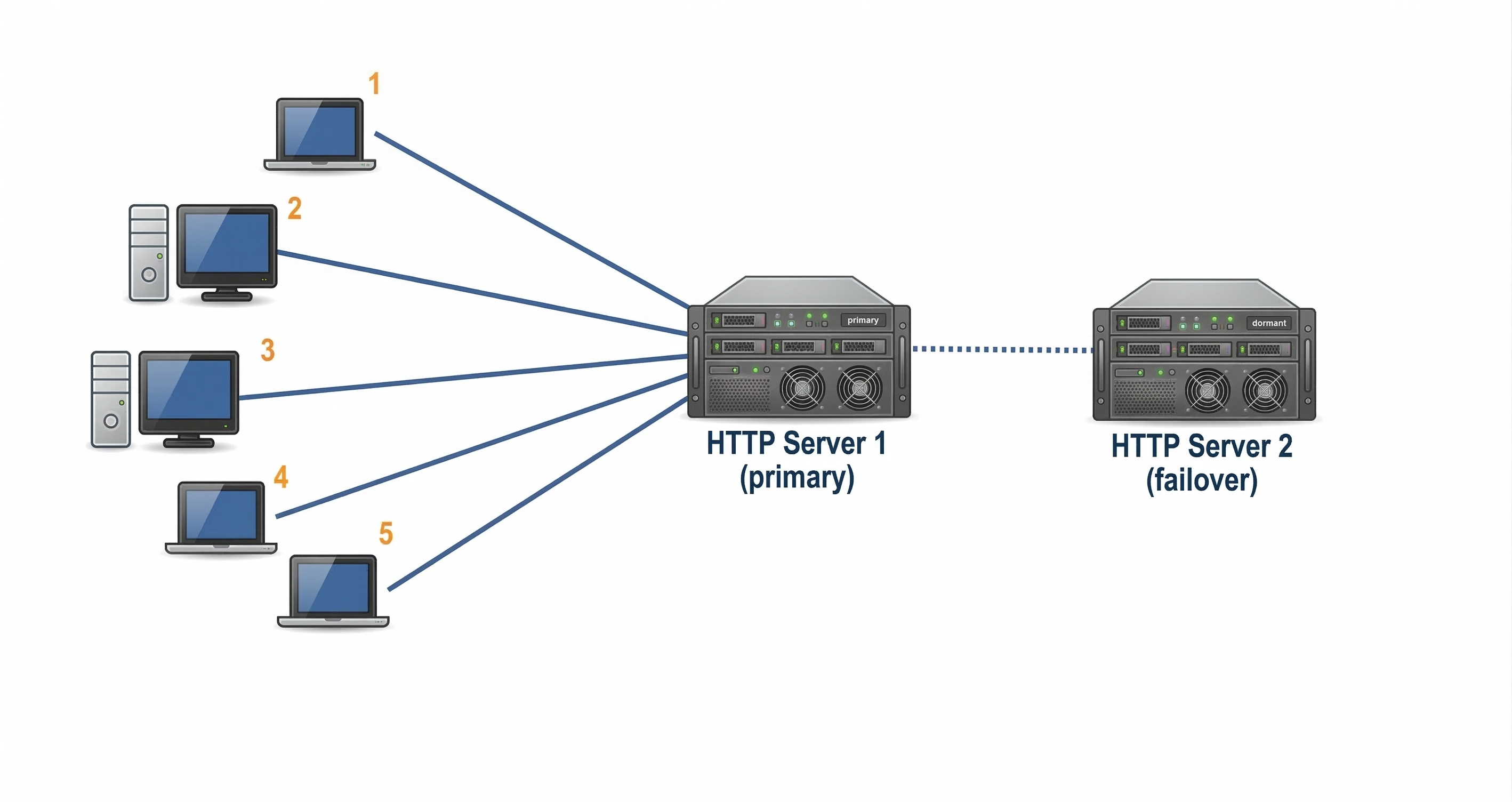
How it works
- Primary server handles traffic.
- Secondary server stays on standby.
- Monitoring detects failure.
- Traffic switches automatically.
Users experience little or no disruption.
Types of failover
Active Passive
- One server is active.
- One server waits idle.
Pros: simple design and easy management.
Cons: hardware is underutilized and backup sync risk exists.
Active Active
- Multiple servers handle traffic simultaneously.
- Load balancer distributes requests.
Pros: better performance, higher throughput, and better resource utilization.
Cons: session handling is complex and configuration consistency is critical.
Replication
Replication means keeping multiple copies of data in different machines or locations.
If one copy is lost, another can be used.
Master Slave Replication
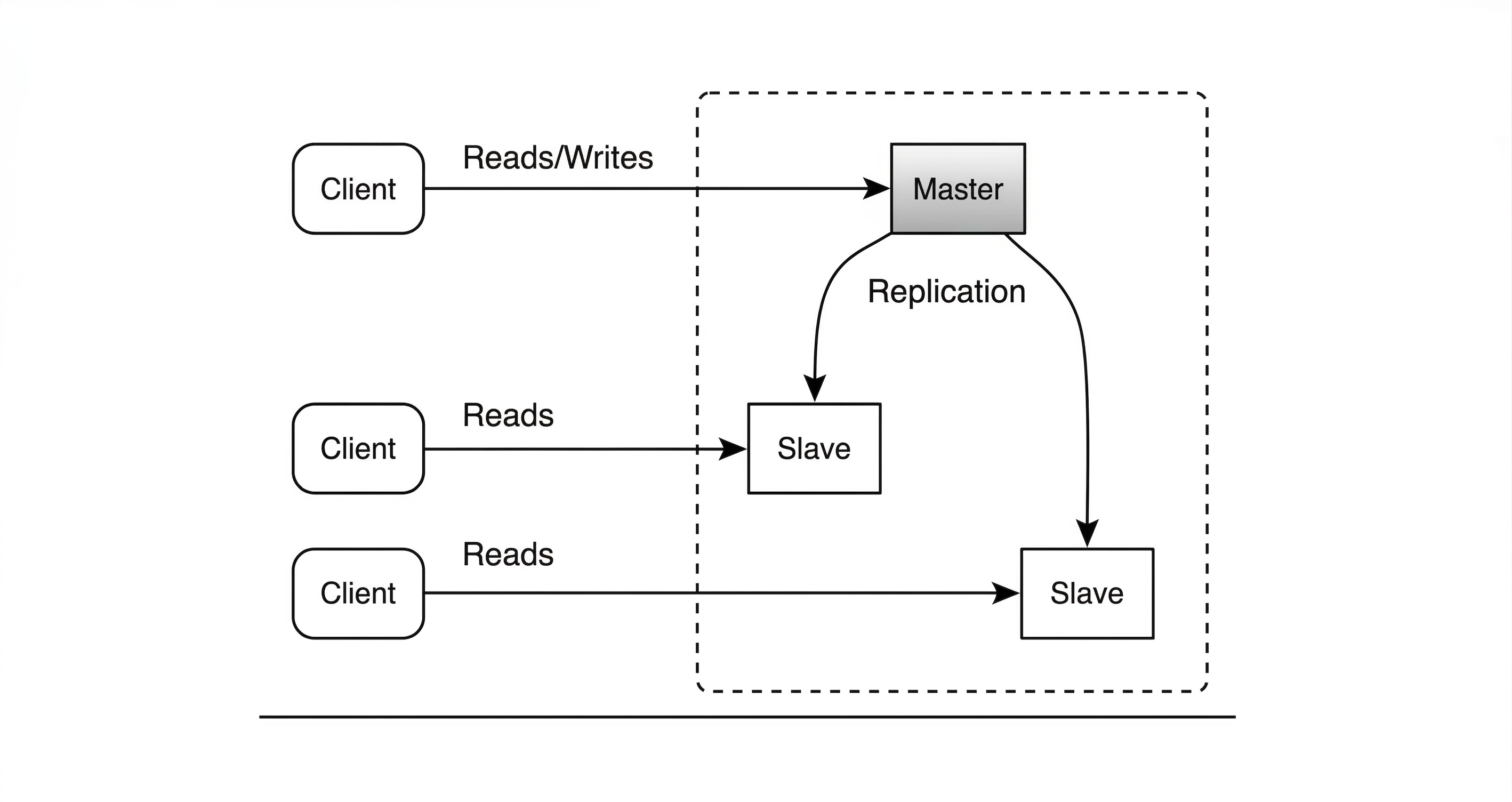
- Master handles reads and writes.
- Slaves handle only reads.
If master fails, the system may continue in read only mode and a slave can be promoted to master.
Master Master Replication
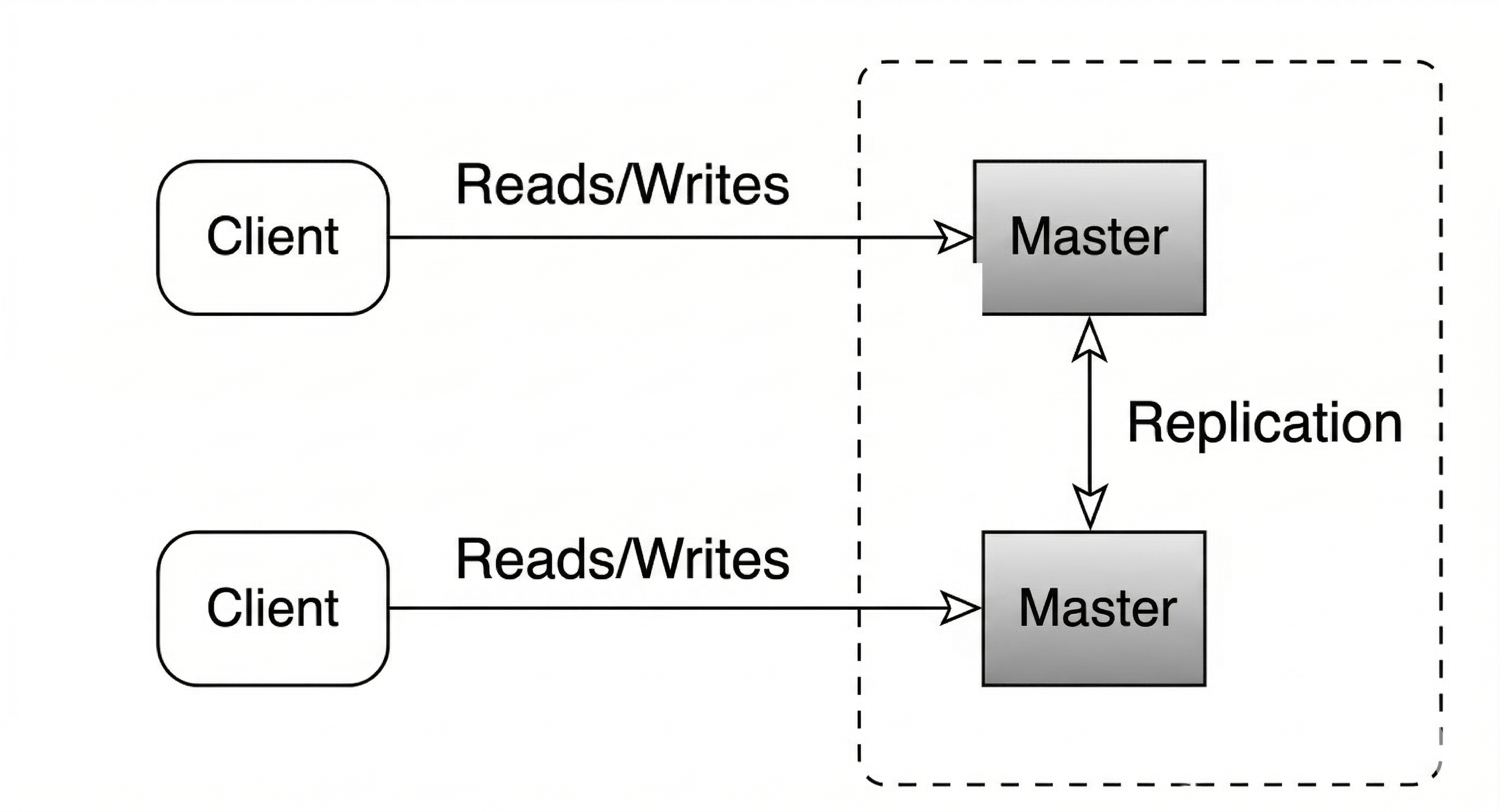
- Multiple nodes handle reads and writes.
- Nodes synchronize data between them.
Benefits: higher availability and no single write bottleneck.
Challenges: conflict resolution, higher write latency, and consistency trade offs.
Trade offs of Replication
Replication improves availability but introduces complexity.
- Possible data loss before replication completes.
- Replication lag under heavy writes.
- Higher infrastructure cost.
- Promotion logic for failover.
Engineering is always about balancing availability, complexity, cost, and consistency.
Final Thoughts
Availability is not just a metric, it is a design mindset.
Building highly available systems means assuming failures will happen and designing the system to survive them.
Good system designers do not try to prevent all failures.
They make sure failures do not break the user experience.