As systems grow beyond a single machine and start running across multiple servers and networks, they become more scalable , but also more complex. One of the most important principles that helps engineers reason about this complexity is the CAP Theorem.
If you understand CAP deeply, many system design decisions start making sense.
This article builds a clear mental model of CAP using practical reasoning and real-world scenarios.
What Is the CAP Theorem?
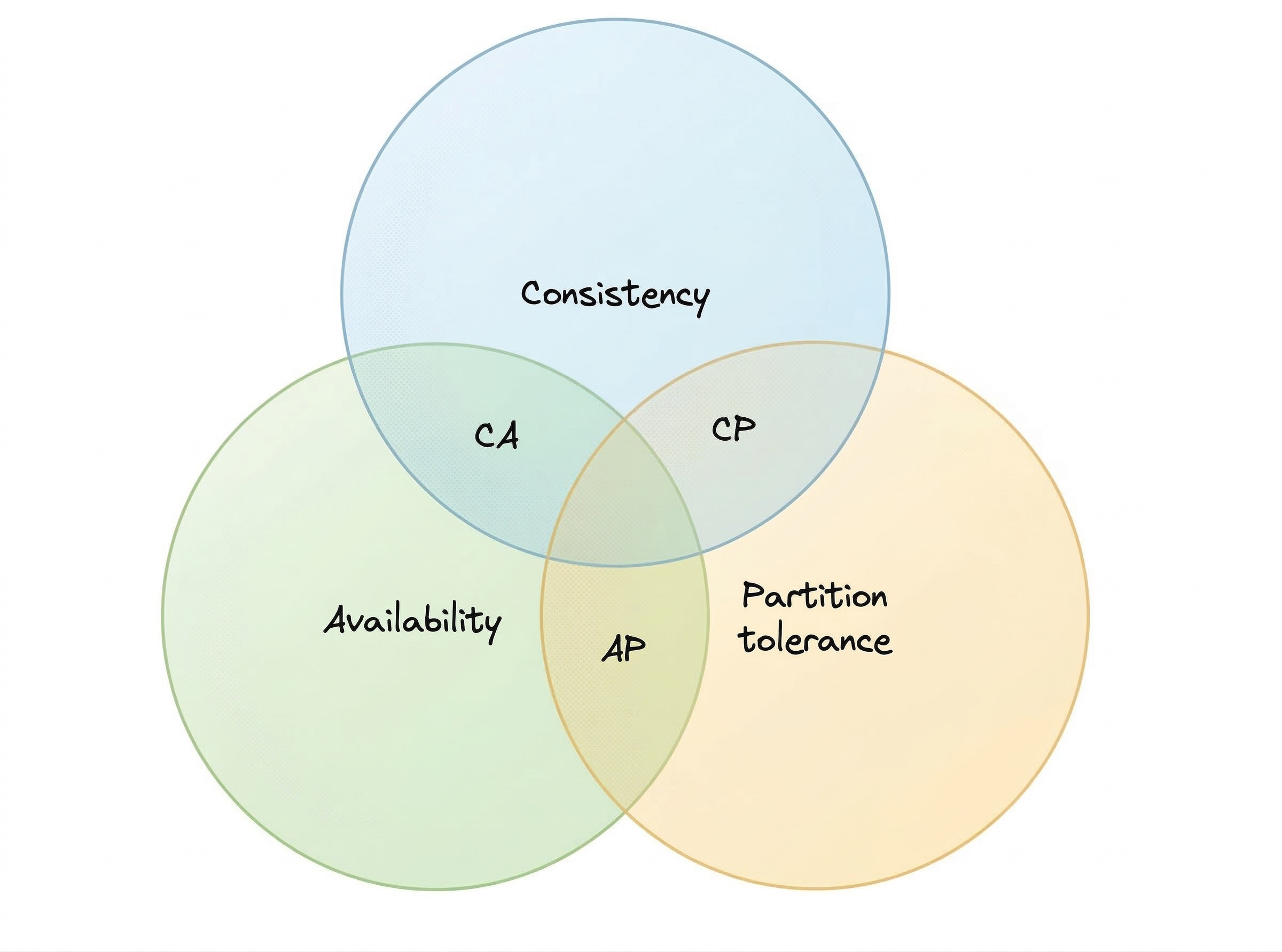
The CAP Theorem states that in a distributed system , a system where multiple nodes share and manage data , you can guarantee only two out of the following three properties at the same time during a network failure:
- Consistency (C)
- Availability (A)
- Partition Tolerance (P)
This is not a theoretical limitation you can engineer your way out of. It is a constraint imposed by the physical reality of networks.
A practical interpretation is: when communication between parts of your system breaks, you must choose whether to return correct data or return a response quickly.
First Understand: What Is a Network Partition?
A partition happens when nodes in a distributed system cannot communicate with each other.
This can happen due to:
- Network cable failures
- Packet loss
- Router crashes
- Cloud region outages
- Extreme latency spikes
Importantly, the nodes themselves may still be running , only communication is broken. From the user’s perspective, the system appears partially alive.
This is the exact situation where CAP decisions matter.
The Three Guarantees in Depth
Consistency
Consistency means that all clients see the same data at the same time, regardless of which node they connect to.
For this to happen:
- When data is written to one node
- The update must be replicated to all other nodes
- Only then is the write considered successful
This ensures there is only one correct version of truth.
Example
In a banking transfer:
- Balance must update immediately
- No user should see the old balance
- Duplicate spending must be impossible
This is a strong consistency requirement.
Availability
Availability means that every request receives a response, even if some nodes are down or unreachable.
The system does not refuse service. However:
- The response may not contain the latest data
- The system prioritizes responsiveness over correctness
Example
A shopping cart service should still allow users to add items even if product inventory synchronization is delayed.
Users prefer a slightly stale cart over a completely broken experience.
Partition Tolerance
Partition tolerance means the system continues operating despite network failures between nodes.
This includes situations like:
- Messages getting lost
- Nodes becoming temporarily isolated
- Data centers losing connectivity
Modern distributed systems must assume partitions will happen. In practice, real distributed databases always choose partition tolerance.
This reduces CAP to a trade-off between Consistency and Availability.
The Core Trade-off: Consistency vs Availability
When a partition occurs, the system must decide:
- Should it block operations to maintain correctness?
- Or should it continue operating and risk serving outdated data?
This decision is not technical alone , it is a business decision.
CP Systems , Consistency + Partition Tolerance
CP systems prioritize data correctness.
When communication breaks:
- Some nodes may stop accepting requests
- Writes may be delayed
- Clients may see timeouts or errors
This prevents inconsistent state.
Typical use cases
- Financial ledgers
- Ticket booking platforms
- Inventory reservation
- Distributed locks and configuration systems
Behaviour during partition
If two nodes disagree about data:
- System pauses progress
- Waits until synchronization is restored
This reduces risk but impacts user experience.
Examples
- MongoDB (in strict consistency modes)
- Apache HBase
AP Systems , Availability + Partition Tolerance
AP systems prioritize system uptime and responsiveness.
During a partition:
- All nodes continue serving requests
- Writes may be accepted independently
- Different nodes may return different data versions
Once the network recovers:
- The system reconciles differences
- Conflicts are resolved using defined strategies
Typical use cases
- Social media timelines
- Shopping carts
- Recommendation engines
- Large-scale analytics dashboards
Users value uninterrupted service more than perfect accuracy.
Examples
- Apache Cassandra
- CouchDB
CA Systems , Consistency + Availability
A CA system can exist only when partitions are assumed not to happen.
This is realistic only in:
- Single-node systems
- Tightly controlled local clusters
- Traditional relational database deployments
Behaviour
- System stays consistent
- System stays responsive
- But fails completely if network splits
Examples
- PostgreSQL
- MariaDB
In internet-scale distributed architectures, CA is rarely achievable because network instability is inevitable.
A Practical Scenario to Make CAP Click
Imagine a messaging platform with servers in Bangalore and Frankfurt.
Suddenly the inter-region network link fails. Now the system must decide:
CP approach
- Stop message sending until connectivity restores
- Guarantees message order and correctness
AP approach
- Allow users in both regions to keep messaging
- Messages sync later
- Temporary ordering issues may occur
Neither choice is universally correct.
The correct answer depends on:
- Product expectations
- Tolerance for inconsistency
- Regulatory constraints
- Revenue impact
Why CAP Matters in System Design
Understanding CAP influences many architectural decisions:
- Database selection
- Caching design
- Microservice communication strategy
- Geo-replication planning
- Failure recovery policies
Ignoring CAP trade-offs often results in:
- Hidden data corruption
- Cascading outages
- Poor scalability
Great system design is about making deliberate trade-offs early.
Final Insight
Distributed systems do not fail only because machines crash , they fail because networks are unreliable.
The CAP Theorem gives engineers a framework to design systems that behave predictably during these failures.
The real expertise is not remembering CAP definitions. It is knowing when the system should protect correctness and when it should protect user experience.